ওভারফিটিং হচ্ছে মেশিন লার্নিং-এর এমন একটি অবস্থা, যেখানে মডেলটি ট্রেনিং ডেটা এতটাই ভালোভাবে মুখস্থ করে ফেলে যে, নতুন বা অদেখা ডেটার উপর ভালোভাবে কাজ করতে পারে না। মডেলটি তখন শুধু ট্রেনিং ডেটার প্রতিটি খুঁটিনাটি তথ্য মনে রাখে, এমনকি ডেটার মধ্যকার অপ্রয়োজনীয় নয়েজ বা ব্যতিক্রমও শেখে। ফলে, যখন মডেলকে নতুন ডেটা দেওয়া হয়, তখন তা বাস্তব বৈচিত্র্য বুঝতে ব্যর্থ হয় এবং ভুলভাল বা দুর্বল ফলাফল দেয়।
সহজ ভাষায়, ঠিক যেমন একজন ছাত্র পরীক্ষার প্রশ্ন হুবহু মুখস্থ করে ফেলে কিন্তু নতুন প্রশ্নের উত্তর দিতে পারে না, তেমনি একটি ওভারফিটেড মডেল শুধু পূর্বের ডেটায় ভালো করে এবং বাস্তব পৃথিবীর নতুন ডেটায় দুর্বল পারফর্ম করে। এজন্য ওভারফিটিং প্রতিরোধ করা খুবই গুরুত্বপূর্ণ, যাতে মডেল শুধু মুখস্থ করা নয় বরং ডেটার আসল প্যাটার্ন বুঝে সঠিক সিদ্ধান্ত নিতে পারে।
তাহলে আপনার আমার সবার মনে একটা প্রশ্ন আসতে পারে যে কিভাবে এই ওভারফিটিং আটকানো যায়?
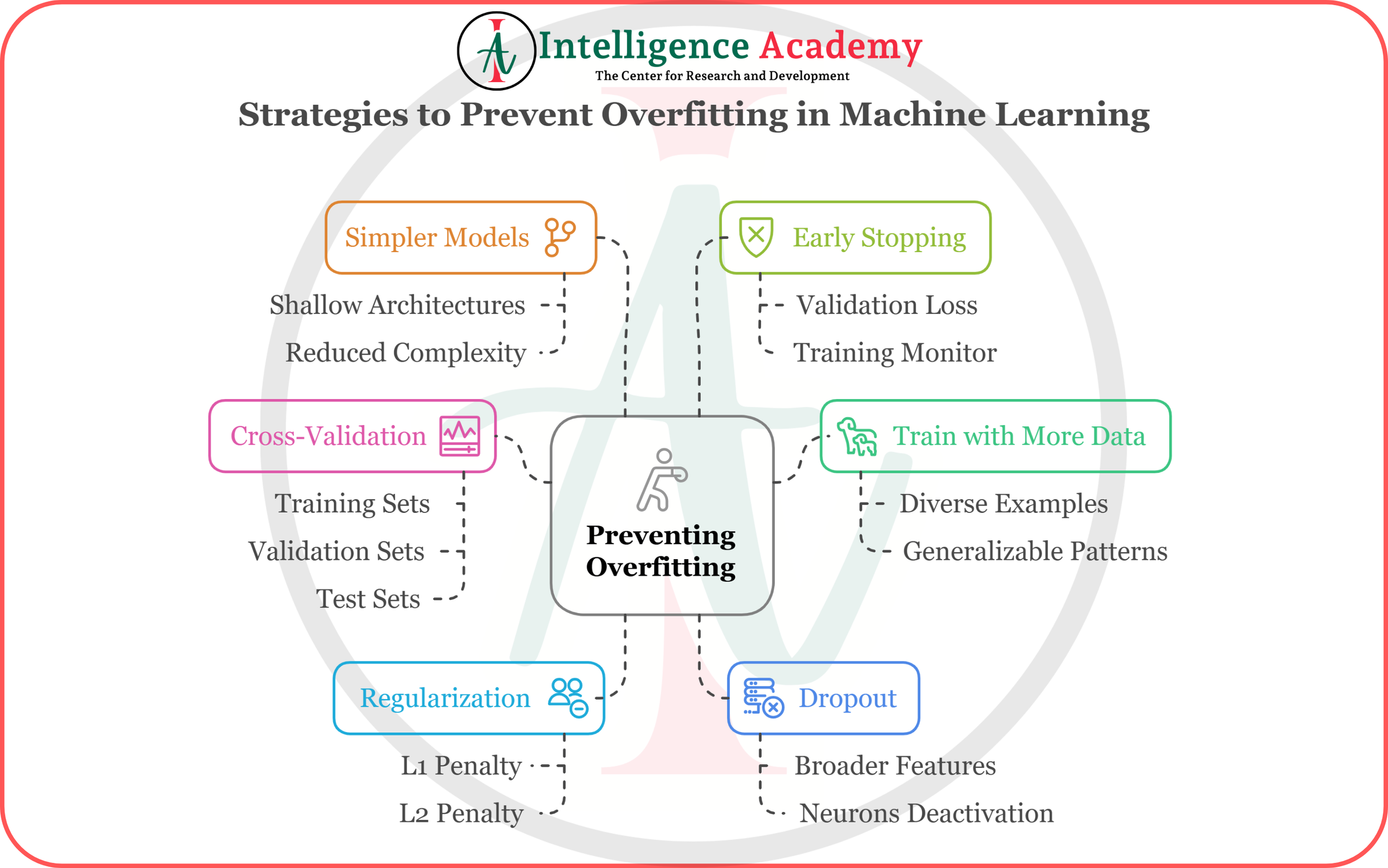
এখন আমরা 6টি গুরুত্বপূর্ণ স্ট্র্যাটেজি বা কৌশল দেখবো, যেগুলো ব্যবহার করে আমরা আমাদের মডেলকে ওভারফিটিং থেকে বাঁচাতে পারি। চলুন এগুলো বিস্তারিত দেখা যাক।
১. Simpler Models (সহজ ও সরল মডেল নির্বাচন করা):
অত্যধিক জটিল মডেল (যেমন: অপ্রয়োজনীয়ভাবে গভীর বা বড় নেটওয়ার্ক) অনেক সময় ট্রেনিং ডেটার উপর অতিরিক্ত নির্ভরশীল হয়ে পড়ে।
✔️ সমাধান:
১.১ Shallow Architectures: মডেলটিকে কম স্তরবিশিষ্ট (shallow) করা।
১.২ Reduced Complexity: ফিচার বা প্যারামিটার সংখ্যা কমিয়ে এনে মডেলকে সহজ রাখা।
👉 সহজ ও সরল মডেল সাধারণত জেনারালাইজেশনে ভালো পারফর্ম করে এবং নতুন ডেটাতে ভুল কম করে।
➡️ উদাহরণ: ধরুন আপনি একটি স্কুলের ছাত্রদের বয়স থেকে তাদের গ্রেড (grade) অনুমান করার মডেল বানাচ্ছেন। এখানে যদি আপনি একটা গভীর নিউরাল নেটওয়ার্ক (Deep Neural Network) ব্যবহার করেন, যেটা ১০+ লেয়ার বা জটিল স্ট্রাকচারের—তাহলে সেটি ছোট ডেটাসেটে ওভারফিট করবে। বরং আপনি যদি একটা সিম্পল লিনিয়ার রিগ্রেশন বা লজিস্টিক রিগ্রেশন মডেল ব্যবহার করেন, তাহলে সেটি কম ফিচার ও কম লেয়ার ব্যবহার করে ভালো পারফর্ম করবে এবং ওভারফিটিং কম হবে।
রিয়েল লাইফে: ছোট স্কেল বা ছোট ডেটাসেটের কাজের জন্য আমরা সাধারণত সরল মডেল বেছে নিই, যেমন Decision Tree-এর বদলে Logistic Regression ব্যবহার।
২. Early Stopping (সময়মতো ট্রেনিং বন্ধ করা)
অনেক সময় মডেল বেশি সময় ট্রেনিং করালে ওভারফিটিং হয়।
✔️ সমাধান:
২.১ Validation Loss: ভ্যালিডেশন সেটে যখন লস বাড়তে শুরু করে বা স্থির হয়, তখনই ট্রেনিং থামাতে হবে।
২.২ Training Monitor: প্রতিটি ইপোক বা ধাপে ভ্যালিডেশন পারফরমেন্স ট্র্যাক করতে হবে।
👉 এটি মডেলকে ট্রেনিং ডেটায় অতিরিক্ত মানিয়ে নেওয়া থেকে রক্ষা করে।
➡️ উদাহরণ: ধরুন আপনি একটি ই-কমার্স ওয়েবসাইটের রিভিউ থেকে পণ্য ভালোমন্দ বুঝার মডেল ট্রেনিং করছেন। প্রথমদিকে ভ্যালিডেশন লস কমতে থাকে, কিন্তু কিছু ইপোক পর দেখলেন ভ্যালিডেশন লস আর কমছে না বরং বাড়ছে। এই সময় আপনি Early Stopping ব্যবহার করলে, মডেল তখনই থেমে যাবে যখন ভ্যালিডেশন লস সর্বনিম্ন ছিল। এতে মডেল বেশি সময় ধরে ট্রেনিং নিয়ে ওভারফিটিং করবে না।
রিয়েল লাইফে: NLP বা ইমেজ ক্লাসিফিকেশন মডেলে যখন লস কমে গিয়ে আবার বাড়তে শুরু করে, তখন Early Stopping ইমিডিয়েটলি কাজে আসে।
৩. Cross-Validation (ক্রস ভ্যালিডেশন প্রয়োগ করা)
একটি ডেটাসেটকে ট্রেনিং, ভ্যালিডেশন ও টেস্ট সেটে ভাগ করে শুধুমাত্র একবার মডেল টেস্ট করা যথেষ্ট নয়।
✔️ সমাধান:
৩.১ K-Fold Cross-Validation ব্যবহার করা।
৩.২ ডেটাসেটকে বিভিন্ন সেটে ভাগ করে বারবার পরীক্ষা করা।
👉 এতে মডেল কতটা জেনারালাইজ করছে সেটা ভালোভাবে যাচাই করা যায়।
➡️ উদাহরণ: ধরুন আপনি ১,০০০ জনের হেলথ ডেটা নিয়ে ডায়াবেটিস প্রেডিকশন করতে চান। আপনি যদি শুধু একবার ট্রেনিং ও একবার টেস্ট করেন, তাহলে ফলাফল খুবই ভাগ্যনির্ভর হবে। কিন্তু K-Fold Cross Validation করলে আপনি এই ডেটাকে ৫ বা ১০টি ভাগে ভাগ করে বারবার মডেল ট্রেনিং ও টেস্ট করবেন।
রিয়েল লাইফে: Kaggle বা অন্য মেশিন লার্নিং কম্পিটিশনে Cross-Validation ছাড়া স্কোর স্টেবল থাকে না। বিশেষ করে ছোট ডেটাসেটে এটি অপরিহার্য।
৪. Train with More Data (আরও বেশি ডেটা দিয়ে মডেল ট্রেনিং করা)
ওভারফিটিং-এর মূল কারণ হচ্ছে ট্রেনিং ডেটা খুব কম হওয়া। কম ডেটা হলে মডেল তা মুখস্থ করে ফেলে।
✔️ সমাধান:
৪.১ Diverse Examples: বিভিন্ন ধরনের ডেটা সংগ্রহ করা।
৪.২ Generalizable Patterns: মডেল যাতে বৈচিত্র্যময় উদাহরণ দেখে শেখে, সেদিকে লক্ষ্য রাখা।
👉 বেশি ও বৈচিত্র্যময় ডেটা মডেলের জেনারালাইজেশন ক্ষমতা বাড়ায়।
➡️ উদাহরণ: ধরুন আপনি ১০০০টি মাত্র ছবি দিয়ে একটি ক্যাট-ডগ ক্লাসিফায়ার ট্রেনিং করছেন। এতে মডেল ক্যাটের গায়ের কালার দেখে বা ডগের নির্দিষ্ট কোন বৈশিষ্ট্য দেখে মুখস্থ করে ফেলবে। কিন্তু যদি আপনি ১ লাখ ছবি দেন, যেখানে ক্যাট-ডগ নানান ব্যাকগ্রাউন্ডে, আলাদা আলাদা রঙে আছে, তাহলে মডেল আসলেই "ক্যাট বনাম ডগ" বুঝতে পারবে।
রিয়েল লাইফে: Google বা Meta-এর মতো বড় প্রতিষ্ঠানগুলো সবসময় মডেল টিউনিংয়ের আগে ডেটা বাড়াতে কাজ করে।
৫. Regularization (রেগুলারাইজেশন টেকনিক ব্যবহার করা)
রেগুলারাইজেশন হলো এমন এক ধরনের পদ্ধতি, যা মডেলের জটিলতাকে নিয়ন্ত্রণ করে ওভারফিটিং প্রতিরোধ করে।
✔️ সমাধান:
৫.১ L1 Penalty (Lasso): কিছু coefficients একদম zero করে দেয়, ফলে কম ফিচার নিয়ে কাজ হয়।
৫.২ L2 Penalty (Ridge): মডেলের বড় coefficients গুলো ছোট করে দেয়, ফলে কমপ্লেক্সিটি কমে।
👉 এটা মডেলের ওজন বা ওজনের মানকে নিয়ন্ত্রণ করে ওভারফিটিং কমায়।
➡️ উদাহরণ: ধরুন আপনি হাউজ প্রাইস প্রেডিকশনের জন্য অনেকগুলো ফিচার ব্যবহার করেছেন (যেমন: বাড়ির সাইজ, লোকেশন, রুম সংখ্যা, রঙ, দেয়ালের ডিজাইন ইত্যাদি)। এখানে রঙ বা দেয়ালের ডিজাইন হয়তো প্রাইসের সাথে খুব বেশি সম্পর্কিত নয়। L1 Penalty (Lasso) দিলে এটি অপ্রয়োজনীয় ফিচারগুলোর ওজন (weight) শূন্য করে দেবে। L2 Penalty (Ridge) বড় বড় ওজনগুলোকে ছোট করে আনবে যাতে মডেল জটিল না হয়।
রিয়েল লাইফে: ফিচার সিলেকশনের ক্ষেত্রে Lasso খুবই জনপ্রিয়, আর Ridge রেগুলারাইজেশন প্রায় সব মডেলের মধ্যে দেখা যায়।
৬. Dropout (ড্রপআউট টেকনিক ব্যবহার করা)
ড্রপআউট হলো নিউরাল নেটওয়ার্কে এমন একটি পদ্ধতি যেখানে ট্রেনিং-এর সময় র্যান্ডম কিছু নিউরন অস্থায়ীভাবে বন্ধ রাখা হয়।
✔️ সমাধান:
৬.১ Broader Features: এটি ফিচারগুলোর মধ্যে ব্যালেন্স তৈরি করে।
৬.২ Neurons Deactivation: কিছু নিউরন ডিঅ্যাকটিভ হয়ে গেলে মডেল সব ফিচারে সমান গুরুত্ব দেয়।
👉 এটি মডেলকে নির্দিষ্ট নিউরন বা ফিচারের উপর অতিরিক্ত নির্ভরশীল হওয়া থেকে রক্ষা করে।
➡️ উদাহরণ: ধরুন, আপনি ইমেজ ক্লাসিফিকেশনের জন্য একটি নিউরাল নেটওয়ার্ক ব্যবহার করছেন। যদি প্রতিবার একই নিউরন বা একই ফিচারের উপর মডেল নির্ভর করে, তাহলে ওভারফিট হবে। কিন্তু আপনি যদি Dropout ব্যবহার করেন, ট্রেনিংয়ের সময় এলোমেলো কিছু নিউরন অফ হয়ে যাবে। এতে মডেল বিভিন্ন ফিচার বা নিউরনকে গুরুত্ব দিয়ে শেখে। ফলে ওভারফিটিং কমে যায়।
রিয়েল লাইফে: CNN বা RNN মডেলে Dropout একটা standard practice হয়ে গেছে।
আপনাদের এক লাইনে মনে রাখার কিছু টিপস দিলাম আশা করি কাজে দিবে আপনাদের:
১. Simpler Model = সহজ পথে হাঁটা।
২. Early Stopping = ঠিক সময়ে থেমে যাওয়া।
৩. Cross-Validation = ডেটা ভাগ করে বারবার যাচাই।
৪. Train with More Data = বই পড়ে নয়, বাস্তব থেকে শেখা।
৫. Regularization = অপ্রয়োজনীয় ফিচার বাদ দেয়া।
৬. Dropout = "সব ডিম এক ঝুড়িতে না রাখা।"
এই স্ট্র্যাটেজিগুলো মেশিন লার্নিং মডেল বানানোর ক্ষেত্রে খুব গুরুত্বপূর্ণ। কারণ, একটি ওভারফিটেড মডেল বাস্তবে (real-world) ভালো ফলাফল দেয় না। তাই মডেলকে জেনারালাইজড এবং স্টেবল রাখতে এই কৌশলগুলো ব্যবহার করা বাধ্যতামূলক।
আপনার মডেল যদি "পরীক্ষায় ভালো কিন্তু বাস্তবে খারাপ" টাইপ হয়ে যায়, বুঝবেন ওভারফিটিং হয়ে গেছে! তখনই এই ৬টি স্ট্র্যাটেজি কাজে লাগবে।
✍️Mejbah Ahammad | COO - Software Intelligence | Intelligence Academy